


A Data Lake is a centralized storage for all your data sources. Its main goal is to enable data processing, including cross-sources processing, with minimal maintenance efforts and costs. At BeeHero we ingest in the Data Lake our IoT data, operational and internal data, 3rd party data, and our production data. This post describes how we implemented ingestion of our production data, stored in an AWS RDS Postgres database.
Our Data Lake implementation is based on AWS S3 files, formatted as Iceberg tables - which supports Data Lake efficiency by semi-structured storage and schema-on-read strategy. Early on we implemented the ingestion of our production data into the Data Lake with a simple solution - copying full tables over from Postgres to the Data Lake storage, via a Glue job which first dropped the Data Lake table entirely and then copied over batches of data from the Postgres table.
This solution however had quickly run out of steam and could not scale to meet our growing data needs. It would take a while to run and was very costly due to the Glue job scale that was needed in order to copy all the data over. The result was that we had to run it in greater intervals, reducing the freshness of the Data Lake data, and still incurring substantial costs. We also ran into issues with our Postgres partitioned tables, where the amount of data was simply not feasible to copy over, and instead we would only copy the last 10 partitions - leading to consistency issues in the Data Lake.
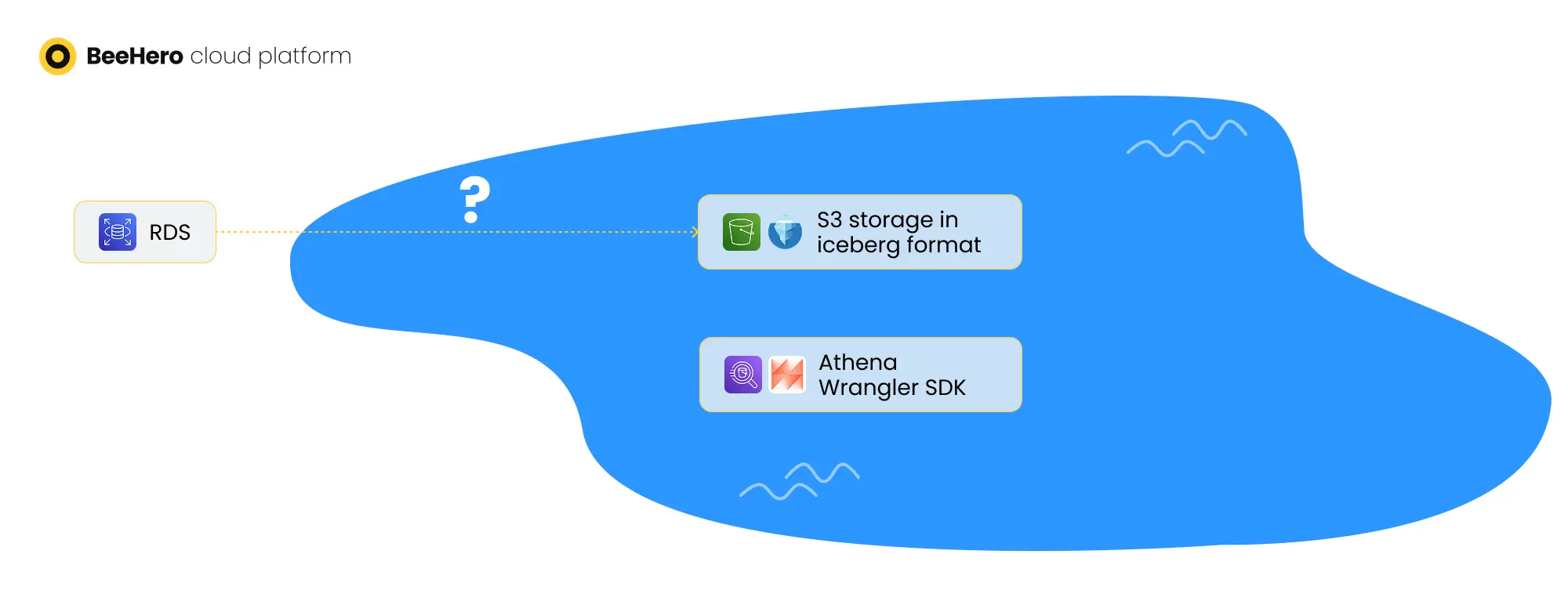
Once the Copy-All solution limitations were evident, we started to design a Change Data Capture (CDC) solution - a continuous detection of changes to the production database that can be then applied in the Data Lake as well. Getting this right is vital, because delays or inaccuracies in CDC propagate errors downstream: stale views, incorrect models, delayed dashboards, or even broken business logic.
Yet implementing a CDC solution is hard because:
We considered several architectures/components for our Postgres to Data Lake CDC, trying to balance the need for a comprehensive and scalable solution with our goal to avoid ‘inventing the wheel’ and leverage ready solutions to minimize our development efforts.
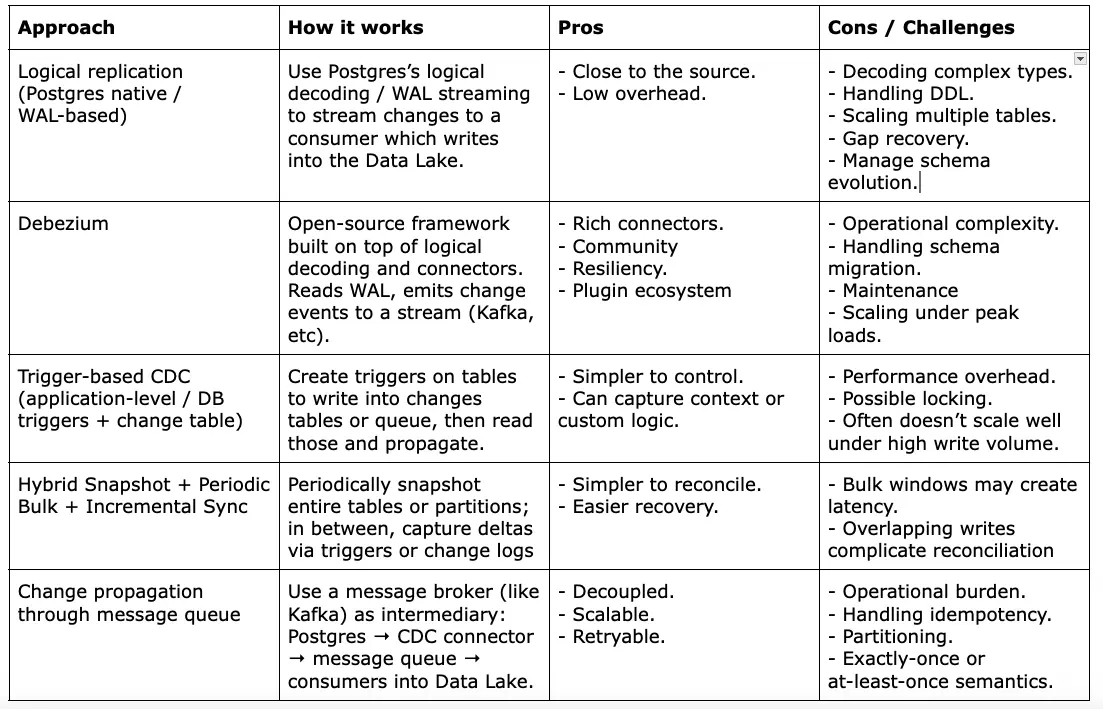
When reviewing these approaches, we debated about multiple aspects:
There were also multiple challenges to consider:
Bringing an existing table (with millions of rows) into the data lake without incurring downtime or duplication is nontrivial. A typical flow is: lockless snapshot (via consistent snapshot or export), then start CDC from the WAL position at snapshot time. Ensuring events are not missed or double-applied requires precise coordination.
When schemas evolve (adding or dropping columns, changing types), old CDC consumers may break, or data may be misaligned. Migration strategies (e.g. support backward compatibility, versioned events) are required.
Suppose the CDC consumer crashes or network blips occur — the component must resume from the correct WAL offset, avoiding skips or duplicates. If events come out-of-order (e.g., update before insert), downstream must handle or reject them.
Emitting CDC from the database must not degrade normal transactional workloads. WAL streaming or replication slots must be tuned to avoid undue disk or CPU overhead.
If multiple tables have dependencies (FKs, join logic), ensuring that the CDC consumer preserves referential consistency or at least handles partial updates carefully is tricky.
After debating these approaches and iterating through several proof-of-concepts, we built a robust and scalable Change Data Capture (CDC) solution based on the message broker approach. This solution balances low latency, fault tolerance, and ease of maintenance — all deployed and managed through AWS CDK for full infrastructure-as-code reproducibility.
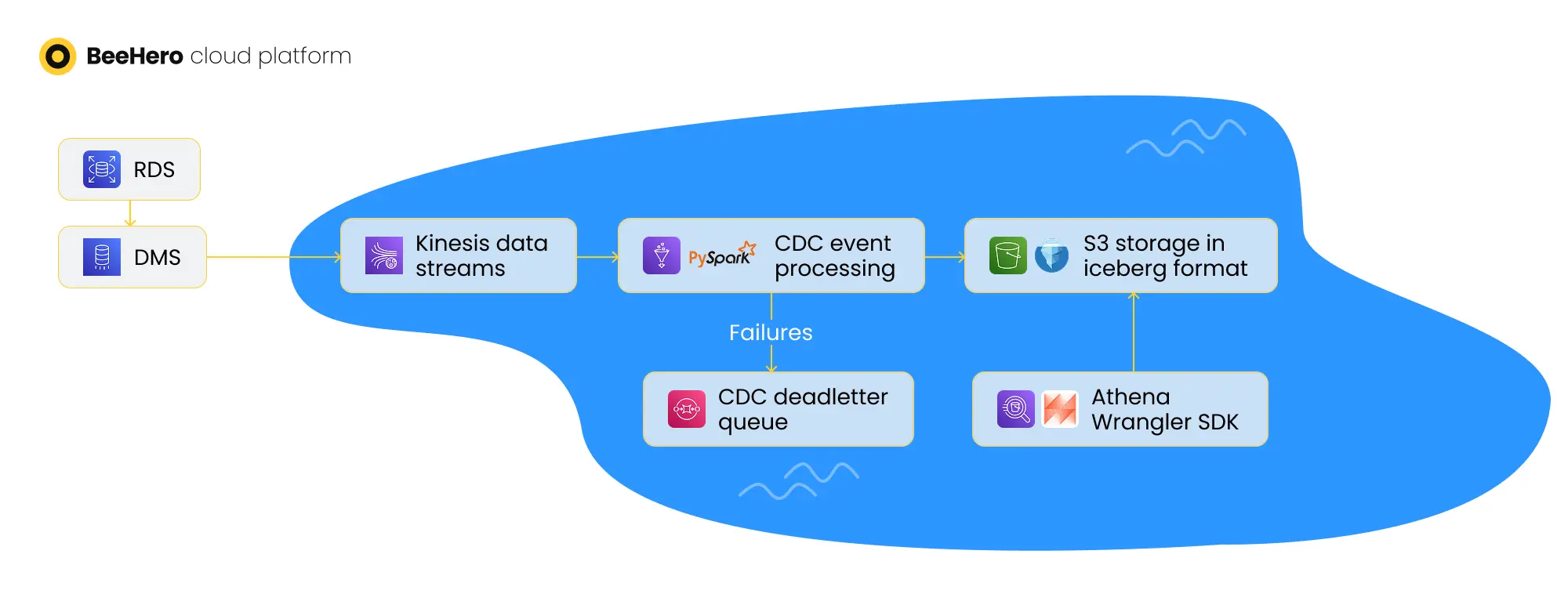
1. Initial Table Snapshot
We begin with a one-time data migration job that moves existing records from Postgres into the Data Lake. This is done via an AWS Glue job, which exports full table snapshots to bootstrap the target storage before streaming begins. This step ensures the Data Lake starts in sync with the operational database.
2. Streaming: Ongoing Change Data Capture
Once the initial snapshot is complete, we capture ongoing changes using AWS Database Migration Service (DMS).
Our configuration uses multiple DMS tasks:
Each task runs in CDC (Change Data Capture) mode with ongoing replication, continuously streaming inserts, updates, and deletes from Postgres in near real time.
3. Kinesis as the Message Broker / Event Bus
The DMS tasks publish all change events into Amazon Kinesis Streams, which serve as our event bus.
Kinesis provides high throughput and ordering guarantees, and we configure a three-day retention window to buffer data and allow for safe reprocessing if needed.
4. Stream Processing: Glue + Apache Spark for Real-Time Transformation
A streaming AWS Glue job, powered by Apache Spark Structured Streaming, consumes the data from Kinesis in near real time. This job is responsible for:
Leveraging Apache Spark gives us the scalability and fault tolerance required to process high-volume data streams with low latency and ensures that our Data Lake remains a real-time, queryable mirror of the operational system.
5. Monitoring and Data Validation
We maintain a comprehensive monitoring and audit framework to ensure accuracy and timeliness across the entire pipeline:
6. Error Handling and Reliability
To ensure resilience and recoverability:
7. Infrastructure as Code with AWS CDK
Every component of this CDC pipeline from Glue jobs to DMS tasks, Kinesis streams, IAM roles, and SNS topics is defined in AWS CDK.
This approach guarantees consistency across environments, simplifies deployment, and enables easy evolution of the system as our schema and scaling needs grow.
This architecture provides BeeHero with a scalable, low-latency, and fully observable CDC pipeline, ensuring that our analytics and machine learning layers always operate on the freshest, most reliable data available - without impacting production systems.


