
At BeeHero, data drives everything, from understanding hive behavior to optimizing pollination business. We pull in data from IoT sensors, mobile apps, Salesforce, finance systems, agronomic observations, and third-party APIs.
As we grew, cracks started to appear in our system:
We needed structure.
Just like bees need a well-organized hive, our data needed a well-organized repository of data definitions.
This is how Data Hive, our DBT-based solution, became the backbone of BeeHero’s analytics and big part of machine learning ecosystem.
DBT (data build tool) lets you manage SQL transformations like code. Instead of scattered queries and ad-hoc views, you get:
Essentially, it lets data analysts work like software engineers.
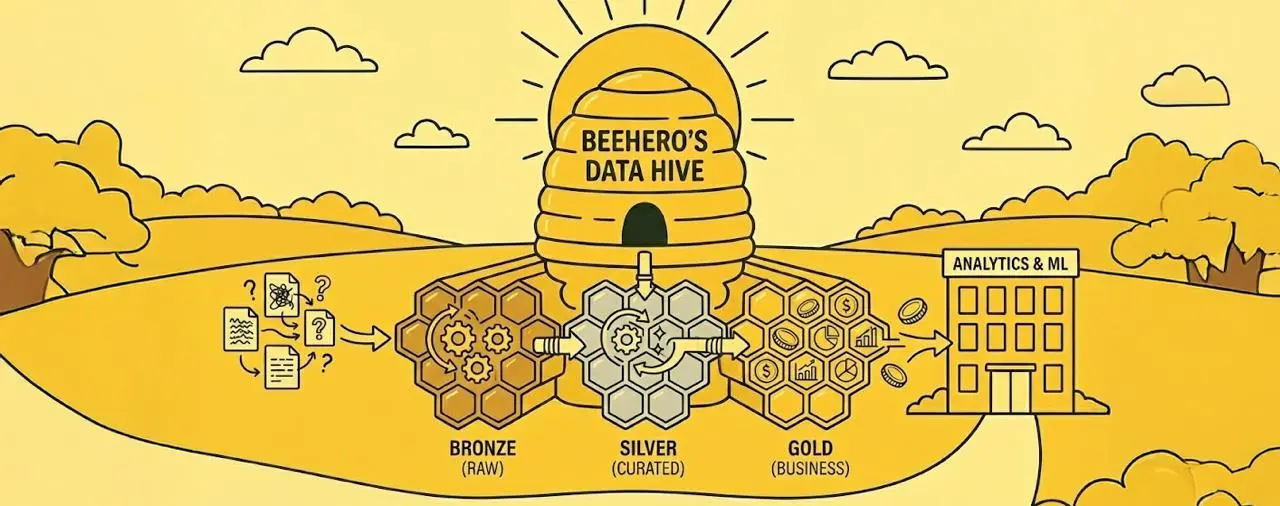
A medallion architecture is a data design pattern for organizing lakehouse data so its structure and quality improve as it moves through each layer: Bronze → Silver → Gold, as explained in the Databricks Medallion Architecture article.
We designed the Data Hive around those layers, each with a specific purpose.
Bronze models are dead simple: they mirror raw data exactly, with zero transformation. They only exist inside DBT.
Bronze acts as our organized doorway into raw data, providing reliable references without adding interpretation.
Silver is where the real work starts. We have two types:
Internal Silver models live only in DBT. They clean, join, filter, and deduplicate data. These are building blocks for other models.
Shared Silver models materialized as views in our data lake. Analysts, ML pipelines, and BI tools all use these. They're clean and consistent, but still granular enough for exploration.
Gold models are where metrics live. These are materialized as actual tables in our data lake and contain real business logic and KPIs.
Gold models are the single source of truth. They power dashboards, finance reports, and ML models. They replace all that duplicated logic that used to be scattered everywhere.
DBT comes with quality controls baked in.
We test for unique keys, null values, valid categories, referential integrity, and custom domain-specific rules. These tests run automatically and catch issues before bad data makes it into production.
Here's where DBT really shines: it generates living documentation that stays in sync with your actual data models.
Every model we build includes descriptions of what it does, who owns it, tags, and detailed explanations of each column. But unlike a Confluence page that goes stale the moment you write it, DBT documentation is part of the code. When you update a model, you update its documentation in the same pull request.
DBT takes all this and automatically builds a searchable documentation website. You can browse through all our models, see exactly what columns exist, read descriptions written by the people who built them, and this is the best part - see the full lineage graph.
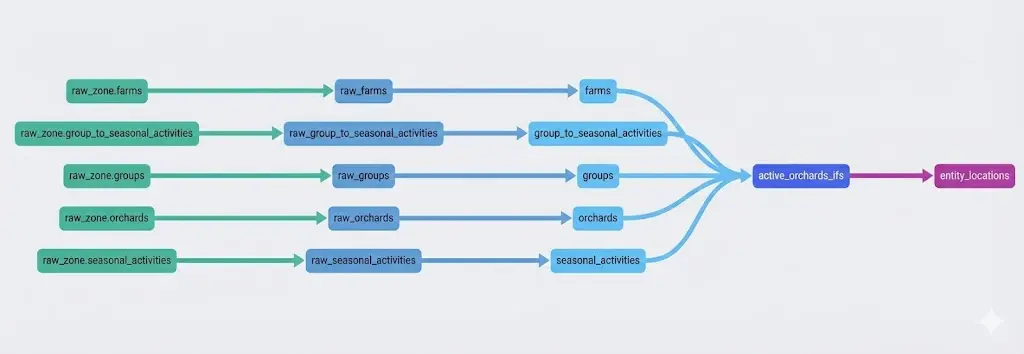
The lineage graph visualize how data flows through the system. Click on any model and you can see:
This means when someone asks "where does this revenue number come from?", you don't need to chase down the analyst who built it two years ago. You just open the docs, find the model, and trace it back through the lineage.
For new team members, this is gold. Instead of spending weeks trying to understand our data architecture through tribal knowledge and Slack messages, they can explore the documentation site and see the full picture in minutes.
And because the docs are generated from code, they're always accurate. If a model changes, the docs change. If a dependency gets added, it shows up in the lineage graph. No manual updates, no documentation drift.
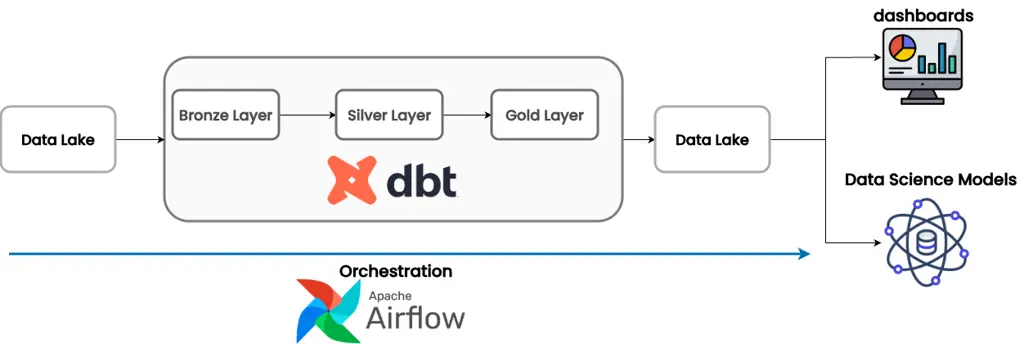
We run DBT using Airflow and Cosmos (a library that integrates the two). This gives us scheduling, retries, backfills, and clear visibility into what's running and when.
It's a huge improvement over our old system where we orchestrated jobs based on schedule and didn’t have the ability to backfill our data.
The Data Hive split responsibilities clearly:
Analysts own business logic, SQL modeling, tests, documentation, and model pull requests.
Engineers own raw data ingestion, materialization strategies, Airflow orchestration, CI/CD, and data lake tuning.
This division keeps things moving fast without stepping on each other's toes.
With DBT and the Data Hive, we now have:
Most importantly: everyone speaks the same language now, using the same definitions and metrics.
We're expanding DBT to more domains, improving Airflow integration, migrating more ETLs, adding incremental models, increasing test coverage, and training more analysts on the platform.
The Data Hive will keep evolving as BeeHero grows.
BeeHero's mission depends on turning messy, real-world data into reliable insights. That requires structure, quality, and teamwork.
DBT and the Data Hive give us exactly that, by treating data like a product: tested, versioned, documented, owned.
This is the hive that powers BeeHero's data-driven future. 🐝


